GPT-4o能拼好乐高吗?首个多步空间推理评测基准来了:闭源模型领跑,但仍远不及人类
上海AI Lab 投稿
量子位 | 公众号 QbitAI
GPT-4o会画吉卜力、会「自拍」,但是能拼好乐高吗?
你有没有想过这样的问题:
多模态大语言模型真的具备理解和推理空间结构的能力吗?
在多步空间推理任务上,现有 MLLMs 究竟表现得如何?
多模态大语言模型真的具备理解和推理空间结构的能力吗?
在多步空间推理任务上,现有 MLLMs 究竟表现得如何?
近年来,随着多模态大语言模型的迅速发展,视觉理解、图文对齐、语言生成等能力不断突破,仿佛人类助手已触手可及。
但在需要多步骤空间感知与逻辑推理的复杂场景中。
例如机器人装配、自动驾驶决策、3D物体理解等,多模态大模型的真实“空间智商”究竟如何?
为此,上海人工智能实验室联合同济大学与清华大学,提出了全新基准LEGO-Puzzles,以乐高拼搭为载体,首次系统评估现有多模态大模型(MLLMs)在多步空间推理(multi-step spatial reasoning)任务中的实际表现。
LEGO-Puzzles:全面覆盖多步空间推理的基准数据集
评估多模态大模型的多步空间推理能力,一个核心挑战是:如何构建既真实又结构清晰的任务?
相比起现实世界视频或图像中的混乱背景和不确定性,LEGO 拼搭过程具备天然的评测优势。它不仅结构规则、每一步明确、空间变化清晰,还拥有高度可控的任务序列。
不同于视频帧之间可能存在的时间逻辑跳跃或视角漂移,LEGO 的每一组装步骤都具有稳定且严密的空间逻辑。此外,视觉多样性也是 LEGO 的一大优势。
各种形状、颜色、组合方式带来了丰富的视觉表达,同时又避免了现实图像中复杂纹理和背景的干扰。
更重要的是,团队基于公开LEGO积木源文件自动生成大规模、可扩展的任务数据,既节省标注成本,又保证高质量与一致性。因此,无论从建模逻辑、可控性,还是数据效率来看,LEGO 都是多步空间推理的理想载体。
依托 LEGO 所具备的结构规则性与空间变化可控性,团队构建了一个专注于多模态大模型多步空间推理能力评估的基准数据集:LEGO-Puzzles。
数据集基于从互联网收集的开源 LEGO 项目源文件,通过 Bricklink 官方软件 Studio 进行渲染,并结合 POV-Ray 生成多视角高质量图像,配合任务模板自动生成问题与选项,最终构建出 1100+ 精心设计的任务样本。
展开全文这些样本覆盖 11 种任务类型,按功能划分为三大类,支持两种任务形式:视觉问答(VQA)与图像生成(Image Generation)。
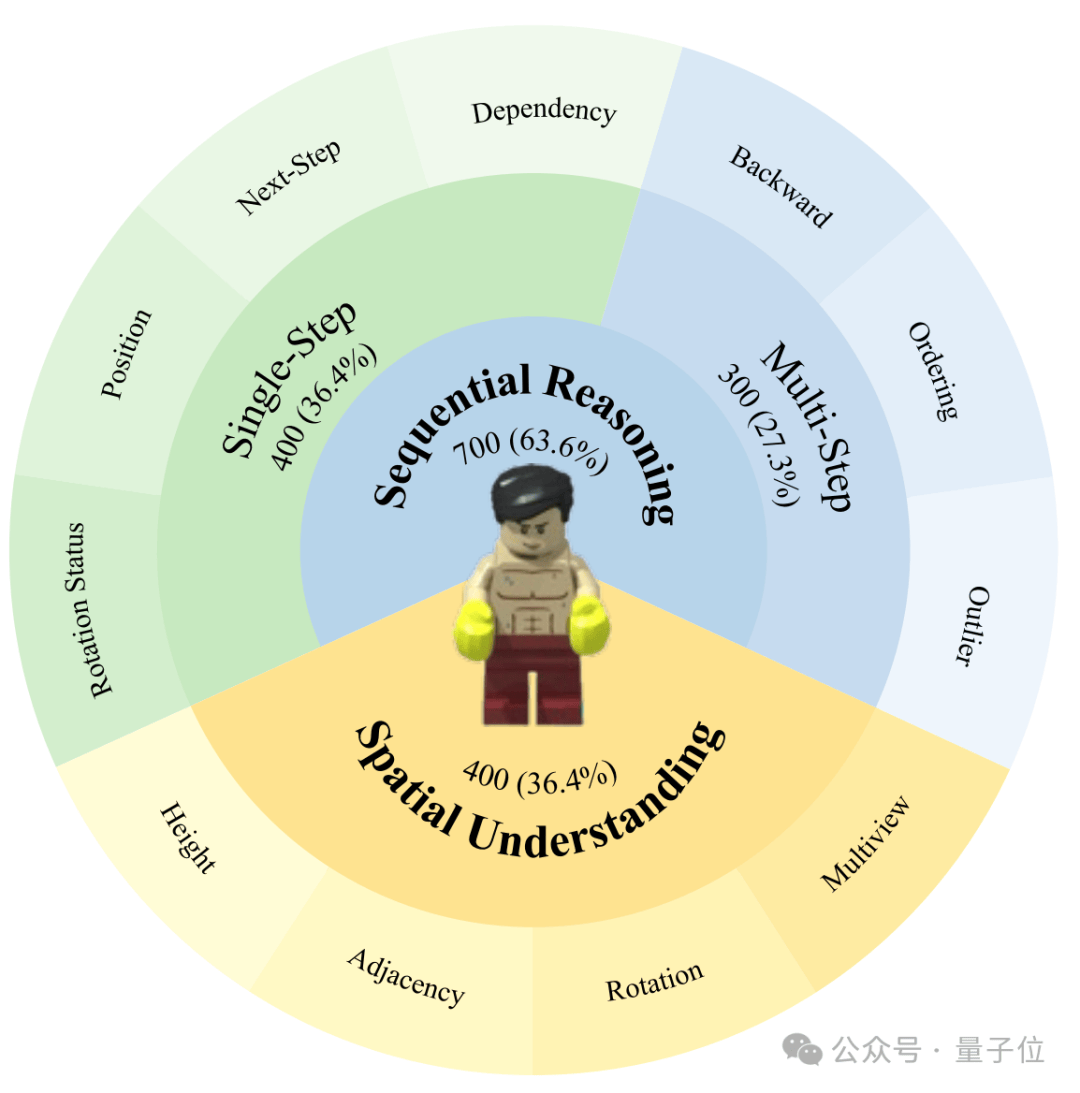
LEGO-Puzzles 的任务设计遵循人类在 LEGO 拼搭中的自然认知流程,从观察结构、执行操作到整体还原,逐步提升任务难度,具体包括:
- ️空间理解(Spatial Understanding): 判断乐高组件的高矮关系、邻接关系和旋转角度;根据不同视角理解乐高结构。
- ️单步推理(Single-Step Reasoning): 评估下一个组件的旋转状态、装配位置,以及装配后的下一步状态和所需组件。
- ️多步推理(Multi-Step Reasoning): 推理装配过程中的中间状态、整体装配顺序,以及识别不符合顺序的异常状态。️
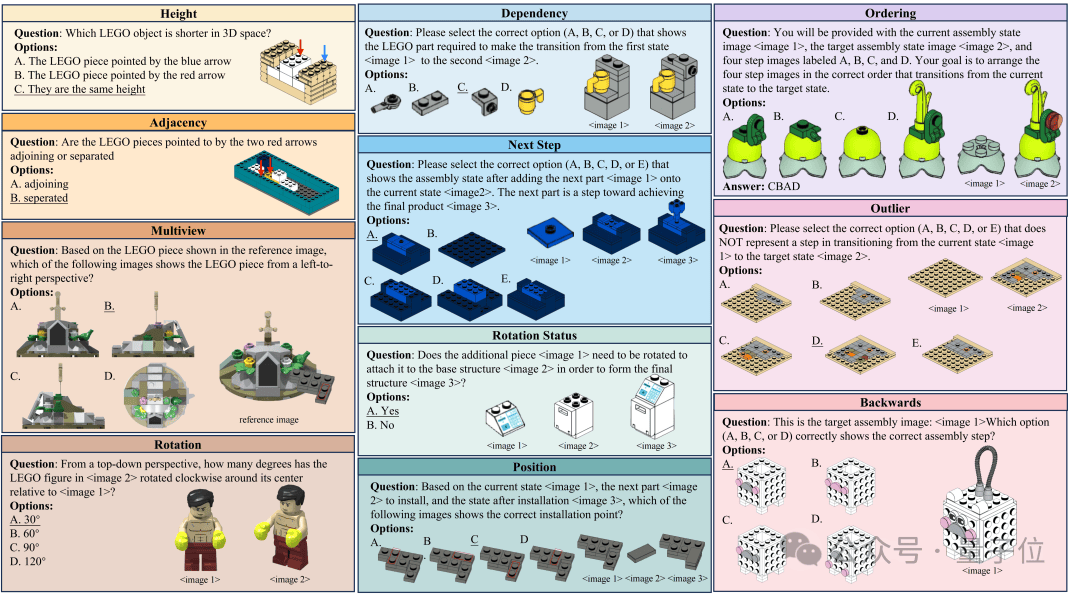
整体任务设置覆盖从基础感知到多步决策,具有高度结构性、序列依赖性与空间多样性。
同时,图像生成版本进一步拓展了评测维度,使得 LEGO-Puzzles 不仅能检验模型“看图做题”的理解力,也能测试“看题画图”的构建能力。
模型表现如何?闭源领跑,但仍远不及人类
团队在 LEGO-Puzzles 基准上系统评测了 20 个多模态大模型(MLLMs),包括GPT-4o、Gemini系列、Claude 3.5,以及Qwen2.5-VL、InternVL等开源模型。涵盖视觉问答(VQA)与图像生成两大类任务。
开源 vs 闭源:能力鸿沟仍明显
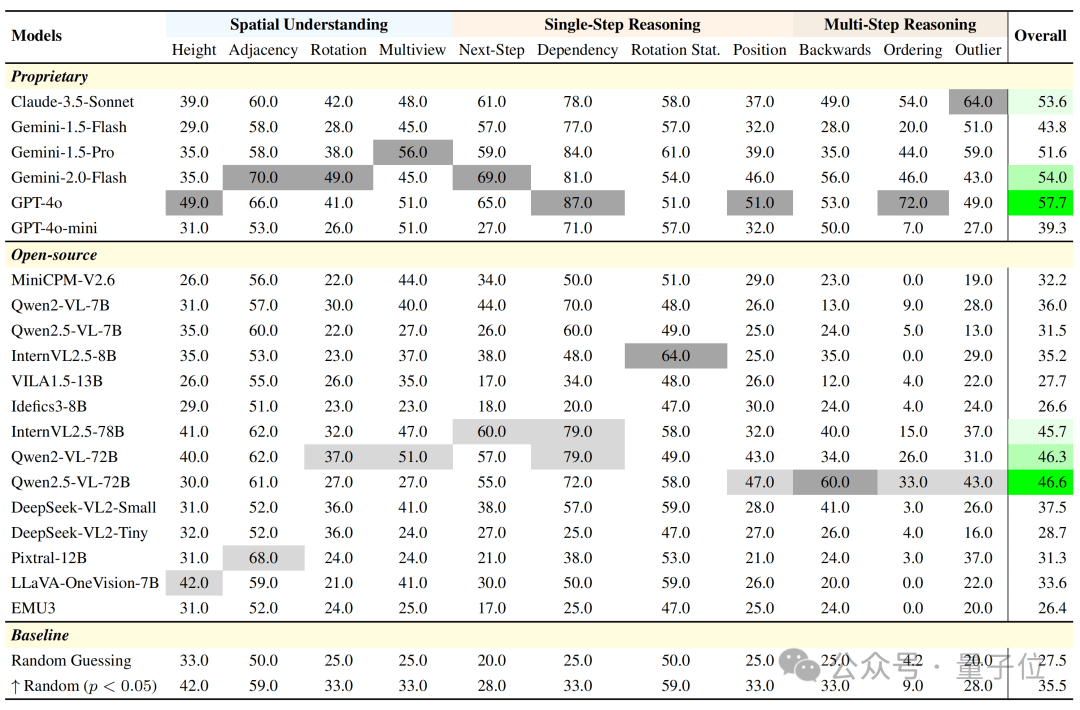
整体来看,️闭源模型在所有任务上普遍优于开源模型。GPT-4o 以 57.7% 的平均准确率位居榜首,Gemini-2.0-Flash 紧随其后(54.0%),而最佳开源模型 Qwen2.5-VL-72B 仅为 46.6%,其余开源模型大多落在 30%~40% 区间,接近甚至低于随机基线(27.5%) 。
在部分关键子任务上,️开源模型的表现不仅不稳定,甚至存在系统性失效。例如在“Ordering”任务中,多达 4 个开源模型准确率为 0,而在“Height”任务中,有一半模型准确率低于随机水平。这表明当前多数开源 MLLMs 还无法建立起有效的空间构型表示或推理路径,特别是在三维结构感知和多步状态理解方面存在根本短板。
MLLMs vs 人类:距离真实智能还有多远?
为了更直观地比较 MLLMs 与人类在空间任务上的表现,团队构建了️LEGO-Puzzles-Lite 子集,从完整数据集中每类任务中随机抽取 20 题,总计 220 个样本,邀请 30 位具备相关专业背景的专家参与答题。
实验结果显示:️人类在所有任务上的平均准确率为 93.6%,几乎在所有任务中都表现稳定。而 GPT-4o 虽然是最强模型,在该子集上仅达到 59.1%。其他模型表现更为逊色,Gemini-2.0-Flash 为 55.5%,Qwen2.5-VL-72B 为 48.2% 。
特别是在多步推理任务中,模型与人类之间的差距进一步被放大。以“Backwards”和“Ordering”为例,GPT-4o 的得分落在 55% 和 60%,而人类均为 95%。这充分说明,当前模型在处理多步空间推理能力上,与人类之间仍有显著认知鸿沟。
图像生成:看得见的空间推理“灾难现场”
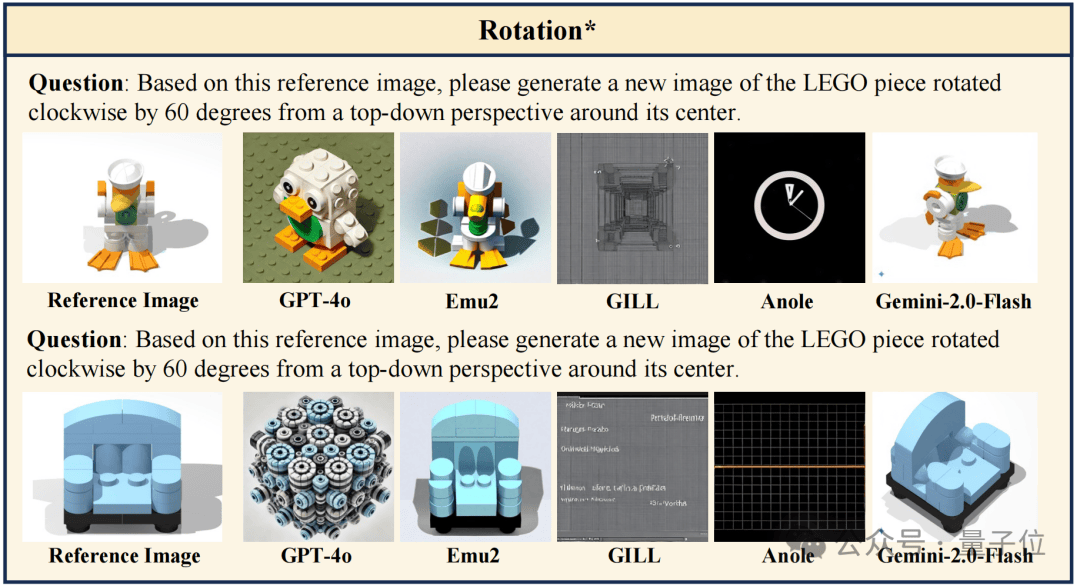
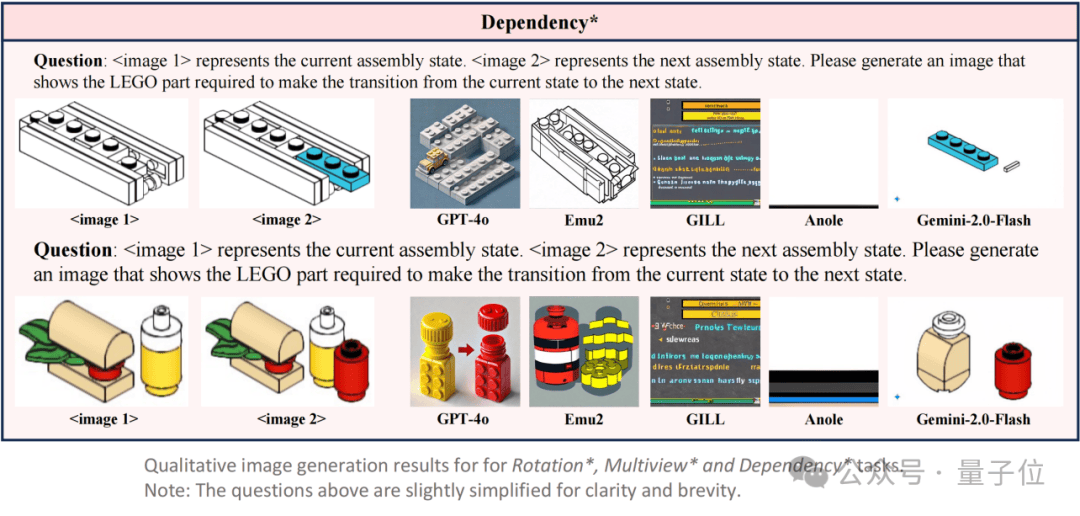
除了视觉问答外,LEGO-Puzzles 还包含了一个专门用于评估视觉生成能力的子集,设计了 5 类图像生成任务,分别对应于主任务中的 Rotation、Multiview、Next-Step、Position与 Dependency。
每个样本要求模型在给定拼搭状态和操作指令的前提下,生成目标结构图像。团队从主数据集中为这五类任务扩展构建图像生成输入输出,并邀请人工专家对生成结果进行双重维度评分:
Appearance(App):图像是否在整体结构上保留了目标状态的特征;
Instruction Following(IF):图像是否准确反映了指定的拼搭操作。
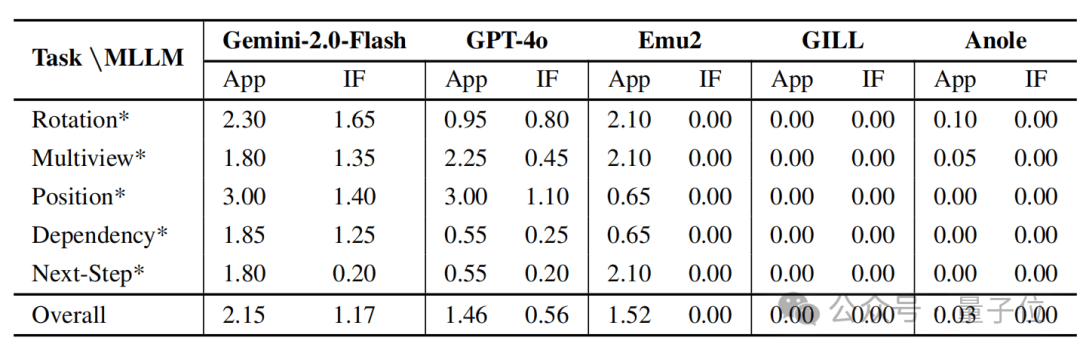

评测模型包含 GPT-4o、Gemini-2.0-Flash,以及开源的 Emu2、GILL、Anole 等具备图像生成能力的模型。
Appearance(App):图像是否在整体结构上保留了目标状态的特征;
Instruction Following(IF):图像是否准确反映了指定的拼搭操作。
评测模型包含 GPT-4o、Gemini-2.0-Flash,以及开源的 Emu2、GILL、Anole 等具备图像生成能力的模型。
结果表明,仅有 Gemini-2.0-Flash 在两项指标上均达到中等及以上水平(App: 2.15 / IF: 1.17),在结构保真度和指令执行力之间保持了较好的平衡。
相比之下,️GPT-4o 的生成过程更像是基于指令语义进行场景重构,而非逐步编辑输入图像。这种策略使得它在指令理解方面表现尚可,但在结构还原方面存在明显不足,️生成图像在细节与整体结构上常常偏离原始图像,导致其 appearance 得分显著低于 Gemini-2.0-Flash。
需要说明的是,本次评测使用的是 2025 年 3 月 6 日前的 GPT-4o 版本,团队也正在测试新版 GPT-4o 的图像生成能力,后续评测中将及时更新。
Emu2 的图像生成与原图外观相似度较高,但几乎无法体现任何操作变化,呈现出典型的“图像重建”行为,缺乏对任务指令的响应。
而 GILL 和 Anole 在所有子任务中基本失效,生成结果与目标结构无关,IF 得分接近于 0,说明它们在空间理解与执行方面均不具备有效能力。
一步能答对,五步就乱了?多步推理让模型“断片”
实验设置中,团队控制拼搭操作步数 k 从 1 增加到 5,逐步加深推理链长度,对模型的连贯性建模与状态记忆能力提出更高要求。输入包括当前 LEGO 状态、接下来的 k 个组件图,以及对应的目标图像和候选选项;模型需从中判断哪一张是合理的拼搭结果。团队还引入 Chain-of-Thought(CoT)提示词,探索“逐步思考”是否能在视觉场景中带来推理性能提升 。
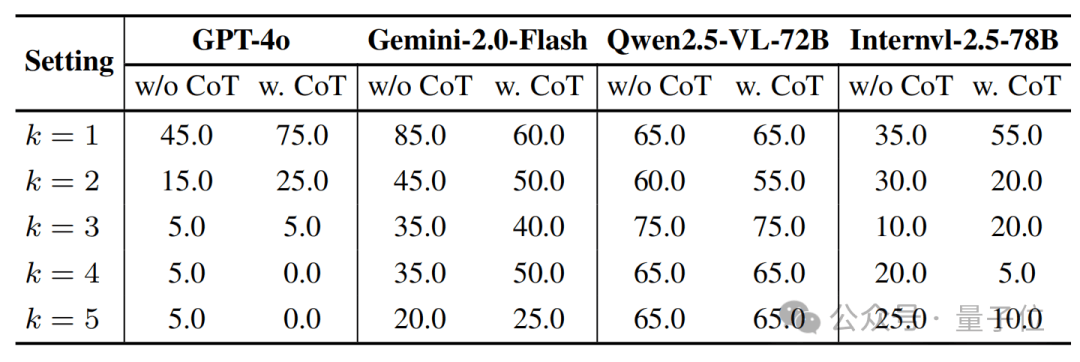
结果显示,大多数模型在 k=1 时仍有一定推理能力,如 GPT-4o 可达 75%(使用 CoT),Gemini-2.0-Flash 高达 85%。
但随着 k 增大,准确率显著下滑,GPT-4o 在 k=4 和 k=5 情况下几乎完全失效,准确率降至 0–5%。
即使引入 CoT 提示,大部分模型在 k > 2 后仍无法维持有效推理路径,说明语言模型中常见的 CoT 技术对视觉多步空间任务的帮助极为有限。
值得注意的是,Qwen2.5-VL-72B 在不同步数下表现相对稳定,准确率始终维持在 65%左右,展现出一定的结构记忆能力;而 InternVL-2.5-78B 则在多数情境下准确率接近随机水平。
这一系列实验揭示出:️当前主流 MLLMs 在处理多步骤空间逻辑时,存在明显的“推理衰减”问题。
总结
团队对当前主流的 20+ 多模态大模型进行了系统性评估,全面揭示了它们在三维空间理解、多步骤空间推理、指令驱动图像生成等关键能力上的表现瓶颈。实验还进一步引入了 Next-k-Step 和 CoT 推理等机制,深入探查了模型在推理链条加深时的稳定性与泛化能力。
LEGO-Puzzles 现已集成至 VLMEvalKit,支持一键评测,快速定位模型的空间推理能力短板。
Paper:https://arxiv.org/abs/2503.19990
Github:https://github.com/Tangkexian/LEGO-Puzzles
HomePage:https://tangkexian.github.io/LEGO-Puzzles


