【验证码识别专栏】某盾躲避障碍与某里图像复原验证码识别

声明
️本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
️本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
前言
近期有粉丝咨询验证码识别相关的问题,是某里 v2 系列中的验证码,其也属于新的验证码类型,但是如果能吃透往期验证码识别相关的文章,这类型验证码的解决方法也是大同小异的。同样,本文也将星球群内,群友的提问一起解决,也欢迎大家随时提问,互相学习:

分析目标
- 地址 1:aHR0cHM6Ly9kdW4uMTYzLmNvbS90cmlhbC9hdm9pZA==
- 地址 2:aHR0cHM6Ly9oYWhhcGlhby5jbi9wYy8jL2dyYWRPcmRlcg==
验证分析
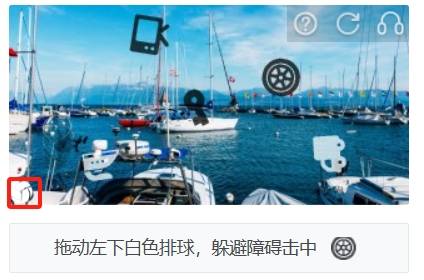
进入验证码体验页面,找到躲避障碍相关的体验页面,发现这类型验证码的背景是由 5 个图标组成的,其中 4 个为障碍物,其中一个为正确答案,而左下角的白球则是固定的,且有半径大小:
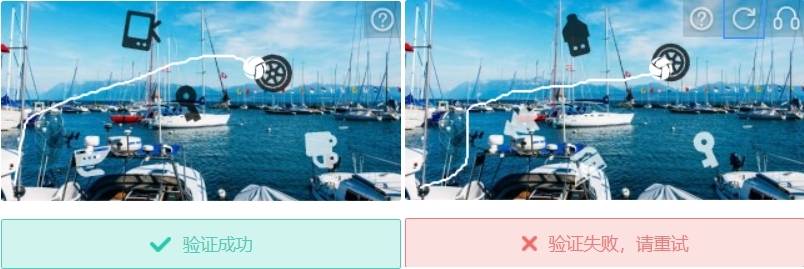
经过分析可知,虽然路径没有碰到障碍物,但是球体本身如果稍微碰到障碍物,或者差一点点碰到障碍物,也是属于验证失败的:
接下来体验的是某里系的图像复原,将缺失的图像在背景图中进行移动,使其复原构成完整的图像。这类型验证码较简单,只需复位即可:

识别分析
障碍躲避
打开验证码体验页,刷新界面,接口得到的图片返回如下,是由原图和目标图拼接而成的:

所以如果我们想拿到目标图(小图),就需要将他从原图上裁剪下来,至于裁剪哪个,这里测试无论是哪个小图都是可以的,默认推荐第一个,代码如下:
url = '图片的URL地址'
response = requests.get(url)
# 将图片内容转换为 numpy 数组
np_data = np.frombuffer(response.content, np.uint8)
# 使用 OpenCV 解码为图像
bg_img = cv2.imdecode(np_data, cv2.IMREAD_UNCHANGED)
char_list = []
char_list.append(bg_img[160:180, 0:20])
至于背景图的检测,可以参考往期文章:
【验证码识别专栏】人均通杀点选验证码:https://mp.weixin.qq.com/s/MgH1obfYrCGivgRvjTX2GA如果觉得 yolo5 过于麻烦可以优先选择 8、11 等版本,相对 yolo5 而言刚方便,泛型也更强,以下是 yolo8 相关参考训练代码:
from ultralytics import YOLO
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
model = YOLO("yolov8n.pt")
model.train(data="icon.yaml", epochs=1, device="0", workers=0, name="icon", batch=32)
path = model.export(format="onnx")
print(1)
配置文件 yaml,这里仅仅把背景所有图标归为一类 0,单纯用作目标检测,如果不追求准确率也可以考略使用 dddd 的检测,相关 yaml 配置如下:
path: datasets # dataset root dir
train: train # train images (relative to 'path') 128 images
val: valid # val images (relative to 'path') 128 images
test: # test images (optional)
nc: 1
# Classes
names:
0: 0
至于预测代码,可以使用官方推理也可以使用生态较好的 fastdeploy,相关代码如下:
import fastdeploy as fd
def build_option():
option = fd.RuntimeOption()
return option
icondetection_model=fd.vision.detection.YOLOv8("best.onnx",runtime_option=build_option())
results = icondetection_model.predict(img_array)
label_ids = results.label_ids
boxes = results.boxes
关于孪生的话,这里推荐 2 个:
- https://github.com/bubbliiiing/Siamese-pytorch (往期文章所用方法)
- https://github.com/2833844911/dianxuan
对于新手玩家的话推荐第二种办法,本文也以第二种方法为主,训练后导出 onnx:
import torch
from text import Siamese
out_onnx = 'model.onnx'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dummy = (torch.randn(1, 3, 105, 105).to(device), torch.randn(1, 3, 105, 105).to(device))
model = torch.load('模型路径')
model.eval()
model = model.to(device)
torch_out = torch.onnx.export(model, dummy, out_onnx,input_names=["x1", "x2"])
预测:
import cv2
import onnx
import onnxruntime
import numpy as np
class ImageSimilarityModel:
def __init__(self, model):
onnx_model_path = 'model.onnx'
self.model = onnxruntime.InferenceSession(onnx_model_path)
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def preprocess_image(self, img):
img_resized = cv2.resize(img, (40, 40)) # 调整图像大小
img_normalized = np.array(img_resized, dtype=np.float32) / 255.0 # 归一化像素值到 [0, 1]
img_transposed = np.transpose(img_normalized, (2, 0, 1)) # 调整为 CHW 格式
return np.expand_dims(img_transposed, 0) # 增加批量维度
def predict_similarity(self, image_1, image_2):
# 对图像进行预处理
preprocessed_img_1 = self.preprocess_image(image_1)
preprocessed_img_2 = self.preprocess_image(image_2)
prediction_output = self.model.run(None, {"x1": preprocessed_img_1, "x2": preprocessed_img_2})
similarity_score = self.sigmoid(prediction_output[0])
# 返回相似度的百分比
return int(similarity_score[0][0] * 100)
那么返回答案中心点坐标,以及去除答案之外的障碍物的全部代码如下:
class ImageProcessor:
def __init__(self,):
self.icondetection_model = fd.vision.detection.YOLOv8("bestjc.onnx", runtime_option=build_option())
self.siamese_model = ImageSimilarityModel()
def slice_icon_img(self, image):
"""
截取图标图像的特定区域。
"""
data = []
data.append(image[160:180, 0:20])
return data
def decode_image(self, bg):
"""
解码编码的图像数据,并返回OpenCV格式的图像。
"""
image_data = .b64decode(bg) # 解码编码的图像
np_data = np.frombuffer(image_data, np.uint8) # 将字节数据转换为NumPy数组
return cv2.imdecode(np_data, cv2.IMREAD_UNCHANGED) # 转换为OpenCV图像
def match_characters(self, txt_list, char_list):
"""
将字符列表中的每个字符与txt_list中的图像进行匹配,返回匹配结果。
"""
data = {'dataset': [], 'image_box': [], 'center': []} # 存储结果的字典
for char in char_list:
best_match = self.find_best_match(txt_list, char) # 查找与字符最匹配的图像区域
# 将匹配的图像和字符添加到数据集中
matched_img = copy.deepcopy(txt_list[best_match[0]]['img'])
data['dataset'].append([matched_img, best_match[2]])
# 获取匹配的图像区域的坐标
x1, y1, x2, y2 = txt_list[best_match[0]]['xy']
# 计算匹配区域的中心坐标并保存
data['center'].append([int((x1 + x2) / 2), int((y1 + y2) / 2)])
# 将匹配的图像区域的坐标添加到image_box中
data['image_box'].append(txt_list[best_match[0]]['xy'])
# 从txt_list中移除已匹配的图像区域
txt_list.pop(best_match[0])
return data
def find_best_match(self, txt_list, char):
"""
在txt_list中找到与给定字符最匹配的图像,返回最佳匹配的索引、相似度分数和字符。
"""
best_match = [0, 0, None] # 初始化最优匹配的默认值 [索引, 相似度, 字符]
for index, txt in enumerate(txt_list):
score = self.siamese_model.predict_siamese(txt['img'], char)
if score > best_match[1]:
best_match = [index, score, char]
return best_match
def get_remaining_boxes(self, xy_list, image_box):
"""
从原始目标区域列表xy_list中移除已被匹配的区域,返回剩余未匹配的区域。
"""
return [n for n in xy_list if n != image_box]
def get_box(self, bg):
"""
主函数:处理背景图像,识别目标区域并与字符进行匹配,返回匹配结果。
"""
img_data = .b64decode(bg)
nparr = np.frombuffer(img_data, np.uint8)
bg = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
results = self.icondetection_model.predict(bg)
xy_list = results.boxes
xy_list = [[int(coord) for coord in box] for box in xy_list]
print(xy_list)
char_list = self.slice_icon_img(bg) # 获取字符区域
txt_list = []
for n in xy_list:
x1, y1, x2, y2 = n
txt_list.append({'xy': n, 'img': bg[y1:y2, x1:x2]})
# 匹配字符和目标区域,并得到匹配结果
data = self.match_characters(txt_list, char_list)
logger.info(data["image_box"])
updated_xy_list = self.get_remaining_boxes(xy_list, data['image_box'][0])
logger.info(updated_xy_list)
logger.info(data['center'])
return data['center'], updated_xy_list
经过上述流程,我们便可以拿到目标物体以及障碍物坐标的全部信息,下面就是本文的主要内容,如何躲避障碍达到终点,这里便要用到 A* 算法, A* 算法 是一种启发式搜索算法,结合了广度优先搜索(BFS)的全面性和贪心算法的高效性。它通过计算每个节点的代价(f = g + h),其中 g 是从起点到当前节点的实际代价(路径长度),h 是当前节点到终点的最佳距离。那么在生成路径的时候我们还要动态判断路径点是否在障碍物的框内, 如果存在于障碍物的范围内,那么 A* 算法 会跳过这个点,并继续寻找其他可以通行的路径。
经过测试发现,上面我们的那种思路生成的路径有个弊端,就是路径会贴着障碍物,这样肯定是不行的:

网上也有不少方法,是通过减少初始 y 来避免路径紧贴的问题的:

这无疑是一种办法,但是底部就顾不上了,最新版本中,障碍物如果途径底部,那么百分之 99 是成功不了,就算肉眼差一丝没碰到也是不行的:
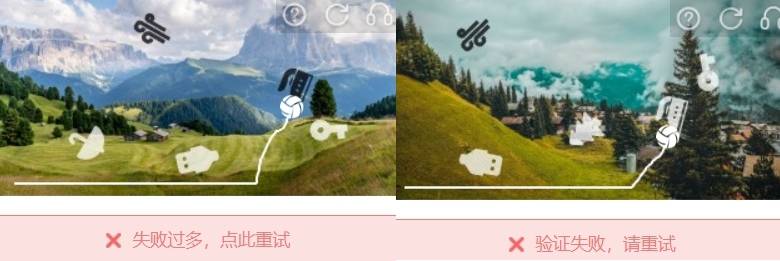
那么,我们可以采取更灵活的方式,便是障碍物膨胀,把障碍物进行二次处理,即使他紧贴的是膨胀后的障碍物,那对真实的障碍物而言也是丝毫不影响通过率的,那么我们思路便是,向左和向上膨胀 8 个单位(防止膨胀超出边界,确保坐标不小于 0),向右和向下膨胀 8 个单位(防止膨胀超出网格范围,确保坐标不大于 GRID_WIDTH 和 GRID_HEIGHT):
def inflate_obstacles(obstacle_boxes):
inflated_boxes = []
for box in obstacle_boxes:
x1, y1, x2, y2 = box
x1 = max(0, x1 - 8)
y1 = max(0, y1 - 8)
x2 = min(GRID_WIDTH, x2 + 8)
y2 = min(GRID_HEIGHT, y2 + 8)
inflated_boxes.append([x1, y1, x2, y2])
return inflated_boxes
膨胀参数一般 6-8 就可以,不仅如此,我们还可以增加一个障碍物,将下面的路给堵死,在返回障碍物框的时候我们自增一个障碍物框 ️all_box.append([87,142,142,158])。
经过测试,多次 100 次后测试后,成功率稳定到 99 左右:


识别失败的我们保存到本地,发现是目标检测的问题,没有框到障碍物导致失败了:

很多人不明白既然膨胀了,为什么还要自己加一个障碍物:

如果我们的目标检测样本数量不是特别多,那么障碍物没有完全框到,即使膨胀那么 A*算法 依旧会选择下方,这时候如果将我们那段障碍物加进去,将下方堵死,那么这种情况就不会错,相反如果你目标检测样本很足,训练拟合很好,单靠膨胀也是可以达到 98+ 的成功率的。
算法以及轨迹生成如下(完整算法可于知识星球获取):
import math
import heapq
import random
import requests
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
from io import BytesIO
GRID_WIDTH = 320
GRID_HEIGHT = 160
# 膨胀障碍物的函数
def inflate_obstacles(obstacle_boxes):
inflated_boxes = []
for box in obstacle_boxes:
x1, y1, x2, y2 = box
x1 = max(0, x1 - 8)
y1 = max(0, y1 - 8)
x2 = min(GRID_WIDTH, x2 + 8)
y2 = min(GRID_HEIGHT, y2 + 8)
inflated_boxes.append([x1, y1, x2, y2])
return inflated_boxes
# 判断某点是否在障碍物内
def is_point_in_obstacle(point, obstacle):
x, y = point
x1, y1, x2, y2 = obstacle
return x1 <= x <= x2 and y1 <= y <= y2
# A*算法的节点类
class Node:
def __init__(self, position, parent=None):
self.position = position
self.parent = parent
self.g = 0
self.h = 0
self.f = 0
def __eq__(self, other):
return self.position == other.position
def __lt__(self, other):
return self.f < other.f
# 启发式函数(欧几里得距离)
def heuristic(a, b):
return math.sqrt((a[0] - b[0])**2 + (a[1] - b[1])**2)
# A*路径规划算法
def astar(start, end, obstacle_boxes):
open_list = []
closed_list = set()
start_node = Node(start)
end_node = Node(end)
heapq.heappush(open_list, start_node)
directions = [(-1, -1), (-1, 0), (-1, 1),
(0, -1), (0, 1),
(1, -1), (1, 0), (1, 1)]
#部分省略,星球自取
#部分省略,星球自取
return []
# 从URL加载图片的函数
def load_image_from_url(image_url):
response = requests.get(image_url)
img = Image.open(BytesIO(response.content))
return img
# 主函数,接收图片URL、障碍物、终点并返回轨迹
def get_trajectory(image_url, original_obstacle_boxes, start, end):
# 从URL加载图像
image = load_image_from_url(image_url)
obstacle_boxes = inflate_obstacles(original_obstacle_boxes)
path = astar(start, end, obstacle_boxes)
if not path:
print("未找到路径")
return []
t_start = random.randint(50, 80) # 初始时间
t_current = t_start
tracks = []
for point in path:
tracks.append([point[0], point[1], t_current]) # 加入时间
t_current += random.randint(5, 10) # 时间递增
# 返回轨迹
draw = ImageDraw.Draw(image)
for box in original_obstacle_boxes:
draw.rectangle(box, fill="red")
draw.ellipse((start[0] - 3, start[1] - 3, start[0] + 3, start[1] + 3), fill="green", outline="green")
draw.ellipse((end[0] - 3, end[1] - 3, end[0] + 3, end[1] + 3), fill="yellow", outline="yellow")
for i in range(len(path) - 1):
draw.line([path[i], path[i + 1]], fill="blue", width=1)
return tracks,image
pointresult, all_box = yd_icon.get_box(base_img)
all_box.append([87,142,142,158])#障碍物添加
start = (10, 150) #起点
#图片url,障碍物信息,起点,目标点中心x,目标点中心y,
tracks,image = get_trajectory(bg_pic_url, all_box, start, (pointresult[0][0],pointresult[0][1]))
某里 v2 图像复原
关于某里图像复原可以参考往期文章:
【验证码识别专栏】今天不炼丹,用 cv 来秒验证码:https://mp.weixin.qq.com/s/YNP7CmjY6nHiGiDARH5UYQ图像复原主要就是将缺失的部分从左到右移动到指定位置:

针对这种类型采用暴力匹配图像灰度图的 md5 值与对应的移动 x 距离,与往期文章旋转验证码识别方法基本相似。
首先需要自己写一个标注工具,将原图和小图进行平移拼接,将拼接后的完整图像保存到新的文件夹中,命名就用 原来图像的名字_移动距离:
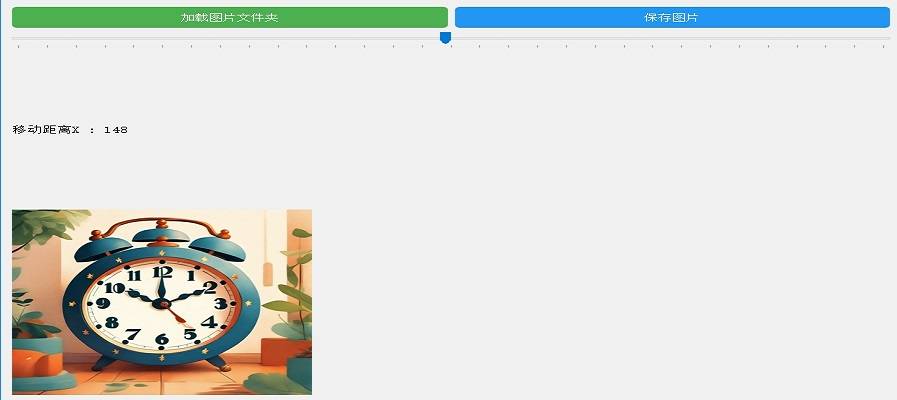
标注好以后,随后通过遍历原图来得到他的 x 移动距离,生成 pkl 文件:
import os
import pickle
import hashlib
import re
import cv2
def calculate_file_md5(image_path):
"""计算文件的 MD5 值"""
md5_hash = hashlib.md5()
# 读取图像并转换为灰度图像
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 将图像编码为二进制数据
success, encoded_image = cv2.imencode('.jpg', img) # 转换为 .jpg 格式
if success:
binary_image = encoded_image.tobytes() # 转为二进制数据
md5_hash.update(binary_image) # 更新 MD5
return md5_hash.hexdigest()
def generate_pkl(bg_folder, newbg_folder, output_pkl_file):
# 初始化两个字典
hists = {}
histsx = {}
# 遍历 newbg 文件夹中的文件(已标注的图像)
for newbg_filename in os.listdir(newbg_folder):
match = re.match(r'(\d+)_bg_(\d+)\.png', newbg_filename)
if match:
angle = int(match.group(1))
image_id = match.group(2)
# 找到 bg 文件夹中对应的原图
bg_filename = f'bg_{image_id}.png'
bg_image_path = os.path.join(bg_folder, bg_filename)
if os.path.exists(bg_image_path):
# 计算图像的 MD5 值(灰度图)
md5_value = calculate_file_md5(bg_image_path)
# 保存 MD5 值和角度值到字典中
hists[bg_filename] = md5_value
histsx[bg_filename] = angle
# 将字典保存到 pkl 文件
pkl_data = {'hists': hists, 'histsx': histsx}
with open(output_pkl_file, 'wb') as pkl_file:
pickle.dump(pkl_data, pkl_file)
print(f"pkl 文件已保存:{output_pkl_file}")
# 调用函数生成 pkl 文件
bg_folder = 'bg' # 原图文件夹路径
newbg_folder = 'newbg' # 标注好的图像文件夹路径
output_pkl_file = 'output.pkl' # 输出的 pkl 文件路径
generate_pkl(bg_folder, newbg_folder, output_pkl_file)
预测代码如下:
import cv2
import numpy as np
import
import pickle
import hashlib
import time
def 2cv(_str, decode_type=cv2.IMREAD_COLOR, intensityalpha=False):
"""
将 编码的图片转换为 OpenCV 格式的图片。
:param _str: 编码的图片字符串
:param decode_type: 解码类型
:param intensityalpha: 是否处理透明度通道(Alpha 通道)
:return: 转换后的 OpenCV 图像
"""
if "," in _str:
_str = _str.split(",")[1]
img_data = .b64decode(_str)
nparr = np.frombuffer(img_data, np.uint8)
img = cv2.imdecode(nparr, decode_type)
if intensityalpha and img.shape[2] == 4: # 处理带 Alpha 通道的图像
output_image = np.zeros((img.shape[0], img.shape[1], 3), dtype=np.uint8)
for i in range(img.shape[0]):
for j in range(img.shape[1]):
alpha = img[i, j, 3]
if alpha > 0: # 只有在透明度大于0时才显示
color_intensity = 255 if i % 2 == 0 else 0
color_value = np.array([color_intensity] * 3, dtype=np.uint8)
output_image[i, j] = (color_value * (alpha / 255.0)).astype(np.uint8)
return output_image
return img
def predict_angle(histmodel, histsx, bgimg, queimg):
start_time = time.time()
# 转换背景图和查询图为 OpenCV 格式
md5bg = 2cv(bgimg, decode_type=cv2.IMREAD_GRAYSCALE)
bgimg = 2cv(bgimg, decode_type=cv2.IMREAD_UNCHANGED)
bgimg = cv2.cvtColor(bgimg, cv2.COLOR_BGR2BGRA)
bgimg[:, :, 3] = 0 # 设置 Alpha 通道透明
queimg = 2cv(queimg, decode_type=cv2.IMREAD_UNCHANGED)
queimg[:, :, 3] = 0 # 设置 Alpha 通道透明
# 计算 MD5 值
success, encoded_image = cv2.imencode('.jpg', md5bg)
binary_image = encoded_image.tobytes()
md5_hex = calculate_file_md5(binary_image)
# 合并直方图加载和特征比较逻辑
maxhist = ''
for histk, histv in histmodel.items():
if histv == md5_hex:
maxhist = histk
break
dis = histsx.get(maxhist, 0) # 获取直方图对应的位移量,默认为 0
end_time = time.time()
print(f"时间: {end_time - start_time}s, 最佳匹配: {maxhist}, 位移量: {dis}")
# 计算两张图的位移量(x方向)
x_distance = int(dis)
h1, w1 = bgimg.shape[:2]
h2, w2 = queimg.shape[:2]
# 创建一个足够大的画布用于显示合成图像
max_height = max(h1, h2)
max_width = w1 + w2 + x_distance
canvas = np.zeros((max_height, max_width, 4), dtype=np.uint8)
# 将背景图和查询图放入画布中
canvas[:h1, :w1] = bgimg
canvas[:h2, x_distance:x_distance + w2] = queimg
return dis # 返回预测的位移量(角度)
def calculate_file_md5(binary_data):
md5_hash = hashlib.md5()
md5_hash.update(binary_data)
return md5_hash.hexdigest()
if __name__ == '__main__':
with open('output.pkl', 'rb') as file:
histograms = pickle.load(file)
histmodel = histograms['hists']
histsx = histograms['histsx']
with open('bg/bg_1027072114.png', 'rb') as file:
bgimg_ = .b64encode(file.read()).decode('utf-8')
with open('que/que_1027072114.png', 'rb') as file:
queimg_ = .b64encode(file.read()).decode('utf-8')
predicted_displacement = predict_angle(histmodel, histsx, bgimg_, queimg_)
print(f"x:为: {predicted_displacement}")
结果展示

完整 A*算法 以及标注工具会上传星球,感兴趣的小伙伴可以自行下载。


