Deepseek崛起,CPO、铜缆、液冷等A股算力是“危”还是“机”?

️杰文斯悖论:从长远来看,资源利用效率的提高将导致总消耗量的增加,而不是减少。
人类的AI时代可能要加速而来了!!!
最近有没有使用Deepseek大模型?感想如何?
作为国产的AI大模型,Deepseek在春节前后算是火爆出圈。凭借其开源且低成本高效的特点,不仅在国内引发关注,深度求索这家国产AI大模型公司更是震动了大洋彼岸的硅谷和华尔街。硅谷连夜开会讨论,美股纳斯达克GPU巨头英伟达(NVDA.O)在除夕前夜大跌16.97%,一夜市值蒸发5900多亿美元(约4万多亿人民币),同时其产业链多股下挫。
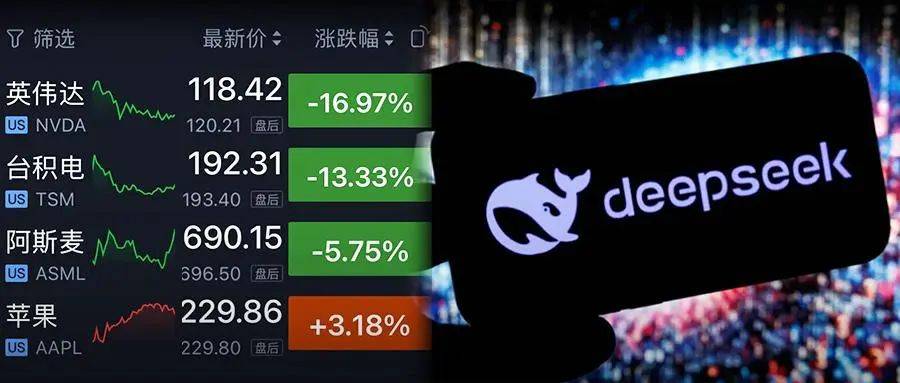
更有趣的是,不久前上台的川普前脚宣布了个千亿美元级别以上的人工智能基础设施投资计划“星际之门”,其中Arm(ARM.O)、微软(MSFT.O)、英伟达、甲骨文(ORCL.N)和Open AI都是关键的初始技术合作伙伴;后脚我们这边就出了一个开源且可媲美OA的一款AI大模型。
包括川普上台后主张的先进制程芯片产业链限制以及高关税等……
展开全文你品,你细品!
01 Deepseek冲击了英伟达的溢价,并未冲垮壁垒
从春节前后的A股市场来看,最惨的应该是A股前期涨势一片大好的英伟达算力产业链,比如CPO光模块概念龙头的中际旭创(300308.SZ)、PCB代表的胜宏科技(300476.SZ)、液冷服务器供应商英维克(002837.SZ)以及铜缆高速连接的沃尔核材(002130.SZ)等,这些细分领域年前年后两个交易日都是遭遇跌停甚至超10%的跌幅,市场一度悲观地认为算力板块崩塌了。
不过,冷静来看,目前市场对于AI产业链短期内确实存在巨大的分歧。乐观者大肆宣传DeepSeek概念板块,各种概念股层出不穷;而悲观者则在前期涨势不错的算力产业链疯狂踩踏。前者神话DS,认为是颠覆性的技术革命,同时疯狂看空美股的英伟达及A股相应产业链;后者则已经有点慌不择路,恐慌抛售。️事实上,短期情绪已占据主导,与其说是看空国内的算力板块,倒不如说是在冲击英伟达以及美股AI头部厂商的超额利润;️而中长期来看,算力产业链并不会崩塌,相反的将迎来一次大爆发,尤其是国产替代环节。只是在这之前,市场需要时间来进行估值及认知的重塑。
借用最近看到的一个比喻:内燃机的高效,只会带来石油的需求高增。
国内DS的发布,实际上确实冲击了算力产业链,不过并非竞争壁垒,而更多是冲击了英伟达等高端算力芯片的超额利润。人类技术发展本就是瞬息万变。️目前市场普遍对于英伟达最大的利空在于算力显卡的价格和贡献或将发生巨大变化,而这个预期将蔓延至中长期。
一直以来,英伟达作为高端GPU供应商,在全球长期处于近乎垄断的市场地位,由于AI的需求爆发,使得英伟达算力芯片的需求高涨。而整个算力芯片市场的竞争态势也就决定了彼时行业龙头的超额利润,也就是英伟达的估值溢价。根据财报来看,2025财年Q3甚至全年预期的业绩依旧抢眼(即2024年业绩),其中Q3的数据中心业务收入达308亿美元,环比增长17%,同比增长112%且创历史新高,业绩增速表明英伟达“曾经”的AI GPU产品的市场需求情况。
分歧就在于此,随着Deepseek的算力成本曝光,市场开始预期英伟达及产业链的超额利润将受到威胁。要知道,英伟达的产品出了名的贵,2024年全年公司的毛利率和净利率一度达到了历史新高,分别在75%和55%以上。️这个盈利能力简直恐怖,包括其业绩增速也是市场给予高估值的原因。
DS的横空出世,等同于昭告天下:️AI大模型其实即使没有使用高端且昂贵的AI算力芯片也能达到预期的领先效果。这或将意味着,全球对高端算力芯片的需求从供不应求转为产能过剩。而英伟达产业链的暴跌,其实也是受到这个逻辑的利空影响:一旦DS的技术路径没有被证伪推翻,未来高端芯片需求缓和,英伟达就不得不消化预期“过剩”的产能,对其下游产业链的需求和订单价值将出现较大的波动。
️产业链的核心风险就在于,A股英伟达产业链的这些上市公司2024和2025年的订单基本都签完了,短期业绩预期也已经反映在股价上。而未来预期,就得看英伟达是否会砍单或降价,️这种不确定性对前面概念板块的公司业绩预期造成了巨大的利空影响。那么既然高端的AI芯片供需预期或发生巨大变化,那就看市场如何重新估值、重塑逻辑以及供需。不过可以肯定的是,DS算法上的创新仅仅冲击了溢价,尚未冲击到竞争壁垒。由此英伟达的股价只是短期下跌,并不会出现崩盘。
总结来看,DS的出现确实是人工智能大模型的重大突破,也的确扰动了全球AI算力市场,其最重大的意义在于推动了全球的AI平权,短期将抹平英伟达、Open AI等厂商的超额利润。而且竞争态势上来看,人工智能也不再是美国一家独大,这主要体现在一来是开源对Open AI闭源的挑战;二来是国产算力芯片对英伟达所代表的高端算力芯片霸权的冲击。
这两点也是海外资本市场利空核心的逻辑。
02 算力需求为何将不减反增?!
算力不会崩塌,而且依旧将是全球各国未来建设的重要方向。
下面一个图就能说明问题。在工作日的上午10-12点这个时间段,在使用深度思考和联网的功能时,DS的用户时常会出现“服务器繁忙,请稍后再试这样的提示”,包括有些用户开始发现其推理能力有所下降。
这背后的原因主要是这段时间DS的用户量激增,硬件有点跟不上。7天用户就破亿,增长了十几倍。而其推理集群并没有完善,很多深度推理和联网都用不了,用户推理需求增长后DS没有及时扩容。这就说明一个问题:在DS注册用户不断创新高的同时,其背后的算力和服务器似乎已经有点不堪重负了。足以可见Deepseek未来大概率是要迅速扩容来应对这样的问题,而对产业链来说,也就是AI大模型对背后的算力基础设施需求还是很高的。

DeepSeek确实很亮眼,且足够优秀。不过这里还要对DS的“神话论”去个媚,辩证的看待新事物才是一个正常的心态。
首当其冲的就是成本端,约600万美元这个数字其实并不准确。根据机构调研的情况来看,这个“600万美金”仅仅是V3模型的训练成本,而V3模型是通过迭代出来的,如果将前期模型的投入加起来的话,成本至少是目前的3-5倍,千万美金的成本还是有的,据了解约是Meta Llama 3成本的四分之一。总结来看,降低AI的成本是肯定的,但绝对没有网传那么玄乎;
️其次,DS依旧需要巨大的算力硬件支持。比如生态方面,虽然DS的出现冲击了英伟达的超额利润,但DeepSeek暂时还是无法绕过对英伟达CUDA生态的依赖,据了解DS是虽然是通过直接调用PTX进行性能的优化,但PTX也是英伟达GPU的中间指令,其代码复杂且移植性差,难以适配其他GPU架构。
事实上,英伟达之所以能够垄断市场,核心壁垒在两点:️一个是硬件之间的NVLink,另一个是CUDA的软件生态;前者为GPU之间提供高速、低延迟的数据传输通道,提高了系统的计算能力和数据处理效率,而后者的CUDA生态凭借软硬件协同、丰富的工具链和行业渗透率构建了难以撼动的竞争优势。
尽管竞品也在高速发展,比如硬件连接端技术相对成熟的PCIe和CXL(Compute Express Link),以及软件生态端的国产华为CANN生态以及摩尔线程MUSA,这些方案确实在开放性和国产化方面展现了潜力,但其成熟度和硬件性能暂时仍无法对NVLink与CUDA造成较大影响。
️再者,DeepSeek确实更像“东方人”,在硬件算力跟不上的情况下,另辟蹊径在算法上进行优化,在架构上使用独立的新MoE,且针对该技术路线,在编译器中间表示层面对算子框架进行了深度融合优化,进而提升了算力的利用率。比起“西方人”对算力的直线思维,我们确实更会转弯。
不过,低成本投入的弊端也很明显,DeepSeek V3专注了文本生成和逻辑推理任务,相对缺乏多模态能力,不久前DS也发布了多模态模型,能够做图像生成,这样的模型出来之后加快了多模态速度,不过成本好像没有公开数据,按理来说大模型多模态的算力消耗是文本模型的10倍左右,推理算力消耗是此前的好几倍。
03 Deepseek如何推动AI大模型的降本增效?
DS最大的意义是打开大模型的发展思路,并且带领AI进入平权时代,那降本增效就是它的核心。所以还是要分析下下DS是如何降低成本,冲击美股AI产业超额收益的。在这之前,需要先了解下训练和推理的成本。
首先是训练端,这个方面对硬件需求较大且成本高。目前来看,️高端的算力芯片依旧是无法被替代的,因为大模型训练依赖高带宽显存、高算力密度及成熟的软件生态,英伟达的GPU短期内仍占主导地位。即使算法优化可以减少单次训练成本,但随着头部企业对大模型性能的竞争加剧,这会驱动更大规模训练,高端算力芯片需求会被维持。只不过DS在算法优化的成就可以一定程度上缓和大模型训练时的投入占比,也就是后面会提到的“预训练”和“后训练”;
这里根据Deepseek的优化路径的特点来看:DS通过稀疏计算、模型蒸馏等方式,显著降低了对高端GPU的依赖;而且DeepSeek-R1采用的核心技术是“后训练”,这也是降低成本的一个关键点。️相比于西方重视“预训练”,希望大模型能成为一个“六边形战士”,所以需要囤卡、堆算力来“喂”海量的全行业数据;但我们的DS通过预训练后,则选择重点进行后训练,也就是“因材施教”,大模型在哪个行业,就只“喂”单一行业的数据,使其成为行业的垂类大模型,也就是我们常说的“专才”。(比如将一个自然语言预训练后的大模型应用于能源领域时,会使用能源领域的文本数据进行后训练)
在重构训练端占比的同时,DeepSeek的这种算法优化路径也重新对️训练和推理的投入占比进行了重新分配,即正在推动行业从 “以训练为中心”转向“推理优先”的模式。根据机构调研这个比例大致在️训练30%,推理70%(不一定准确,但是个趋势参考)。而资本市场预期的核心变化也基于此:占比的变化给国产专用芯片带来了巨大的需求潜力。
因为在大模型的推理端,对高端芯片的需求就那么高了。
DeepSeek带动下,这种轻量化模型的增加会将推理场景向边缘转移,进而带动专用AI芯片(如ASIC芯片和FPGA等)的需求增加,不过ASIC也有明显的痛点:️软件支持不足,且硬件壁垒较弱,且短期内高端算力芯片在云端推理(如批量处理、复杂任务)中依然还是存在巨大优势,但DeepSeek发布已经创造了一定的需求空间和弹性,算是给国产芯片等算力产业链“杀”出了一条路。
04 结语
DeepSeek的横空出世意义重大,更像给AI产业安上了“另一条腿”。
不过DS的兴起并不代表另一方的衰败,这种算法结构优化,确实能提升单次的任务效率,降低大模型的成本。然而多模态、复杂推理、通用人工智能等这些AI能力的边界扩展却依旧需要更大规模训练和算力支持,算力和算法从不是相生相克,而是相辅相成。两者并行才会使得AI大模型“如虎添翼”。

更大的意义在于:DeepSeek的降本增效,在冲击英伟达等高端芯片超额利润的同时,也给国内算力产业带来了巨大的需求潜力,降低了发展大模型的门槛。可以这样理解:
在DS发布之前,只有全球头部的大型数据中心可以搞算力和数据中心,为了头部竞争,这些都是斥巨资屯了上万张高端显卡来堆算力,那时候的中小型数据中心是没有机会,毕竟成本过高;
而在DS之后,门槛降低了。头部的大型数据中心依旧会继续屯,毕竟预期高端算力芯片需求变化,价格趋势走低,而头部的预算充足(比如字节、阿里),他们要进行残酷的头部竞争。但是更显著的好处在于中小型数据中心不再需要“万卡”规模,而是“千卡”甚至更小的规模就能实现大模型的预期效果,比如高校、科研等这类预算相对不充足的需求方。
由此来看,对于算力的需求短期走低后,中长期依旧是向上放量增长的,而且需求更大。毕竟DS的出现为中小型数据中心的算力成本降了一个数量级。
最后呢,不必“神话”大模型。预期这些AI大模型的壁垒终究还是会被打破的,而“算力基建”依旧是重要竞争壁垒。因此,那些A股能挤进英伟达算力产业链的头部供应商,一定程度上也会在软硬件国产化中获得不错的机会。而且从大模型的归途来看,还是要与终端AI的应用场景相结合,比如人形机器人、智能驾驶、可穿戴产品、大金融、医疗医药等行业,由此推断这些板块中低估的细分领域或个股标的预期走强的概率将大幅增加!
毕竟我们有最好的AI落地的沃土。


